| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- python
- mysql
- datetime
- 딕셔너리
- enumerate
- lower_case_table_names
- 소수
- Codeforces
- 리스트 컴프리헨션
- SUM()
- timestamp
- 2557
- 파이썬
- itertools
- Dictionary
- 네이밍
- convention
- BOJ
- SUM
- floor
- 에라토스테네스의 체
- ceil
- 큰 수 나누기
- project euler
- flask
- list comprehension
- FOREIGN KEY
- 자료구조
- 세그먼트 트리
- 외래키
- Today
- Total
목록전체 글 (475)
늒네 기록
백준 6749번은 solved.ac 가서 브론즈 V 중에 안 푼 문제가 하나 있길래 들어가보게 되었다. 문제는 정말 단순하다. 셋째, 둘째의 나이가 각 줄에 순서대로 주어졌을 때 첫째의 나이를 구할 것. a, a+d가 주어졌을 때 a+2d를 최대한 적은 연산으로 찾으려면 어떻게 할지 고민해보는 것도 좋겠다. 나는 다음과 같이 풀었다. a,b=int(input()),int(input()) print(2*b-a)
프로젝트 오일러 13번 문제는 파이썬으로 푼다고 하면 거저 먹는 문제다. 큰 수 연산 문제는, 특히 난이도가 낮은 문제라면 파이썬에서 특별히 신경 써야 하는 부분이 적어진다. 문제에서는 100개의 50자리수가 주어지고, 이를 다 더한 다음 앞의 10자리 수를 구하라고 한다. 이런 유형의 문제를 쉽게 푸는 환경을 세팅하는 것에 이 포스트의 의의를 두겠다. 가장 간단한 방법은, 먼저 코드 자체에 100개의 숫자로 이루어진 리스트를 두고 합을 구하는 것이다. 코드는 다음과 같다. l = [ 37107287533902102798797998220837590246510135740250, ... 53503534226472524250874054075591789781264330331690 ] print(sum(l)) 이..
프로젝트 오일러 7번 문제는 10001번째 소수를 찾으라는 문제다. 에라토스테네스의 체를 활용하여 나이브하게 접근하는 것을 시도해보도록 하자. 먼저, 1부터 10000사이에 있는 소수의 개수를 찾는 것부터 시작해본다. n = 10001 l = [False for _ in range(n)] p = [] for i in range(2, n): if not l[i]: p.append(i) for j in range(i, n, i): l[j] = True print(len(p)) #1229 해당 코드에서는, 크기 10001짜리(즉, 마지막 인덱스가 10000) 리스트 l에 대해서 전부 False를 할당해두고 i = 2일때부터 시작해서 만일 l[i]가 False이면 리스트 p에 더하고 (즉, p는 소수들이 들어있..
 [mysql] 테이블 네이밍 컨벤션 2, lower_case_table_names
[mysql] 테이블 네이밍 컨벤션 2, lower_case_table_names
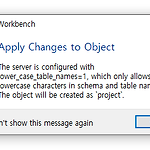
[mysql] 테이블 네이밍 컨벤션 글에서 '테이블 이름 및 칼럼 이름 파스칼 케이스 사용'을 하겠다고 했었는데, MySQL Workbench로 로컬 인스턴스에 연결해서 'Project'라는 이름의 테이블을 생성하려고 했더니 다음과 같은 에러가 발생했다. 설정이 1로 되어있어서 Project 테이블 이름을 project 테이블로 바꿔서 생성하겠다고 한다. 파스칼 케이스를 사용하고 싶다면 해당 설정을 변경하면 그만이겠지만, 이런 설정이 존재하는 데에는 분명 이유가 있을 것이다. 해당 키워드를 가지고 검색을 하다보면, mysql 레퍼런스 매뉴얼 페이지가 나온다. In MySQL, databases correspond to directories within the data directory. Each tabl..
다음과 같은 리스트를 만들고 싶다면 어떻게 해야할까? l = [ [0], [0,1], [0,1,2], [0,1,2,3], [0,1,2,3,4] ] 이전에 쓴 list comprehension 글에서 사용한 방법을 각 아이템마다 적용해보면 다음과 같다. l = [ [i for i in range(1)], [i for i in range(2)], [i for i in range(3)], [i for i in range(4)], [i for i in range(5)] ] 그런데, 여기에도 규칙이 있지 않은가? range 안에 있는 숫자가 [1,2,3,4,5] 안에 있는 숫자로, 너무나도 range로 표현하면 좋겠다는 생각이 든다. 저걸 j for j in range(1,6)으로 표현한다고 하고, 저 리스트 자..
[python] string을 list()하면 어떻게 될까? 글에서 이어서, 문제 링크는 프로젝트 오일러 32번. 39 × 186 = 7254 같이, 곱하는 두 수와 곱한 결과에 1부터 9까지 숫자가 다 들어가는 경우를 찾으면 되는데, 이게 뜻하는 것은 결국 str(i) + str(j) + str(i*j)의 결과에 1부터 9까지 숫자가 모두 포함되어 있다는 것과 같다. 그런데 위에서 string을 list로 바꾸는 것이 쉽게 가능함을 보았으니, 이를 바로 활용하면 sorted(list(str(i)+str(j)+str(i*j))) == list('123456789') 이 조건이 true인 경우를 찾는 문제로 바뀐다. i, j중 작은 숫자가 100 이상일 경우, 3자리수 * 3자리수가 최소 5자리수이므로, ..
간단한 실험. s='1234'일때 list(s)값은? s = '1234' print(list(s)) # ['1', '2', '3', '4'] 간단하게 각 글자를 하나씩 리스트 아이템으로 분리해버렸다! 비슷하게 set(s)를 해도 작동한다. 이 성질을 활용하면 project euler 32번에 쉽게 접근할 수 있다. 내용은 [PE] Project Euler 32 글에 이어서.
문제 풀때 get함수를 아래와 같이 사용할 때도 종종 있다. l = [1,2,2,3,1,2,3,1,4,2,3,4,2,1,2,3,4,1] x = {} for i in l: x[i] = x[i]+1 if x.get(i) else 1 print(x) # {1: 5, 2: 6, 3: 4, 4: 3} 물론, x.get(i) 대신 i in x로 쓰는 것이 더 짧고 직관적이긴 하지만...
파이썬에서 딕셔너리를 다룰 때 종종 마주칠 수 있는 상황. x = {} for i in range(5): x[i] = i*i # x = {0: 0, 1: 1, 2: 4, 3: 9, 4: 16} for i in range(10): print(f'x[{i}] = {x[i]}') #x[0] = 0 #x[1] = 1 #x[2] = 4 #x[3] = 9 #x[4] = 16 #Traceback (most recent call last): # File "cf.py", line 8, in # print(f'x[{i}] = {x[i]}') #KeyError: 5 x 안에 없는 키(위의 경우, 5)를 가지고 불러오려고 하는 경우, KeyError가 발생하며 돌던 것이 죽어버린다. 그렇다면, 처음부터 안에 들어있는 key들..
[7, 17, ..., 87, 97]을 만들고 싶으면 어떻게 해야 할까? 1. 빈 리스트를 만들고 하나씩 더한다. l = [] for i in range(10): l.append(i*10+7) print(l) # [7, 17, 27, 37, 47, 57, 67, 77, 87, 97] 2. 리스트 컴프리헨션 l = [i*10+7 for i in range(10)] print(l) #[7, 17, 27, 37, 47, 57, 67, 77, 87, 97] 당장 가독성 측면에서 l에 값 하나씩 집어넣는 것보다 l을 이루고 있는 값이 어떻게 만들어졌는지 보는 편이 이해하기에 훨씬 수월한데다가, 코드를 작성하는 단계에서도 생각한 걸 더 바로 옮길 수 있고, 심지어 더 짧다.